
Aprendizado de máquina distribuído na rede Akash com Ray
Nesta postagem, fornecemos uma visão geral do desafio de tentar paralelizar e dimensionar cargas de trabalho de IA e ML na prática, apresentamos brevemente a melhor estrutura de código aberto disponível e em uso pelas principais equipes de aprendizado de máquina (Ray), falamos sobre por que Ray é um ótima solução para executar cargas de trabalho de ML na Akash Network e fornece um exemplo e modelo de referência para quem deseja executar um cluster Ray na supernuvem de GPU da Akash Network.
Fundo
A proliferação de modelos de IA e ML de código aberto no ano passado permitiu que os desenvolvedores criassem aplicativos em um ritmo bastante rápido. Isso inclui não apenas inferência, mas até mesmo o ajuste fino de um modelo para adaptá-lo a conjuntos de dados personalizados e necessidades de aplicativos e, em alguns casos, até mesmo o treinamento de um modelo básico. Bibliotecas de código aberto de Pytorch, Tensorflow, Keras, Scikit-learn e outras permitiram que aqueles sem vasta experiência em IA e ML criassem com relativa facilidade aplicativos baseados em Python que aproveitam recursos avançados de IA. O desafio então passa a ser a capacidade de escalar horizontalmente as cargas de trabalho para aproveitar um grande número de computadores, de modo a poder acelerar o tempo de lançamento no mercado e/ou executar um serviço em produção e escalá-lo em resposta à demanda do usuário.
Este conceito de pegar uma carga de trabalho de ML construída para ser executada em uma única GPU (servidor) e permitir que ela seja executada em vários servidores GPU (referido como “cluster”) é o que é chamado de “clustering” e “escalonamento” . O desafio, claro, é que, para fazer isso, o aplicativo que foi construído para rodar em um único servidor precisa ser paralelizado para rodar em múltiplas máquinas. Fazer isso “nativamente” (adicionando suporte diretamente no código do aplicativo) exigiria um conhecimento avançado da infraestrutura em nuvem e da computação paralela. Isso cria uma barreira técnica para poder lançar e dimensionar tais aplicações.
Ray para salvar o dia!
Ray é uma estrutura de código aberto que permite que desenvolvedores de software não treinados em sistemas distribuídos aproveitem facilmente a computação distribuída. Ele faz isso eliminando a necessidade de paralelizar nativamente um aplicativo de aprendizado de máquina e, ao mesmo tempo, permitindo que os cálculos sejam ampliados em um cluster de servidores. Isso permite que os desenvolvedores de IA e ML expandam facilmente seus aplicativos ou cargas de trabalho em um cluster de servidores, sem precisar escrever código adicional para isso ou entender os detalhes da infraestrutura subjacente.
Alguns dos recursos que Ray oferece incluem:
Escalonamento automático: pelo menos em teoria, um cluster de raios cria a abstração virtual de um único computador em um cluster distribuído que pode ser muito grande.
Tolerância a falhas: ao redirecionar automaticamente tarefas para outras máquinas, quando um ou mais nós falham, Ray permite resiliência que é crucial para cargas de trabalho de treinamento de IA de longa duração e/ou inferência em escala de produção.
Gerenciamento de estado: com suporte integrado para compartilhamento e coordenação de dados entre tarefas e flexibilidade para usar uma variedade de opções de armazenamento, incluindo na memória (redis ou equivalente), bem como armazenamento em nuvem (equivalente a S3).
Tempo de execução do Ray AI (AIR)
O objetivo final de Ray é fornecer uma interface programática simples para que os desenvolvedores aproveitem a computação distribuída, para que você não precise ser um especialista em sistemas distribuídos para poder implantar, executar, dimensionar e gerenciar sua carga de trabalho de ML em um cluster de máquinas. O Ray AI Runtime (AIR) é o kit de ferramentas que implementa essa abstração além da funcionalidade principal do Ray.
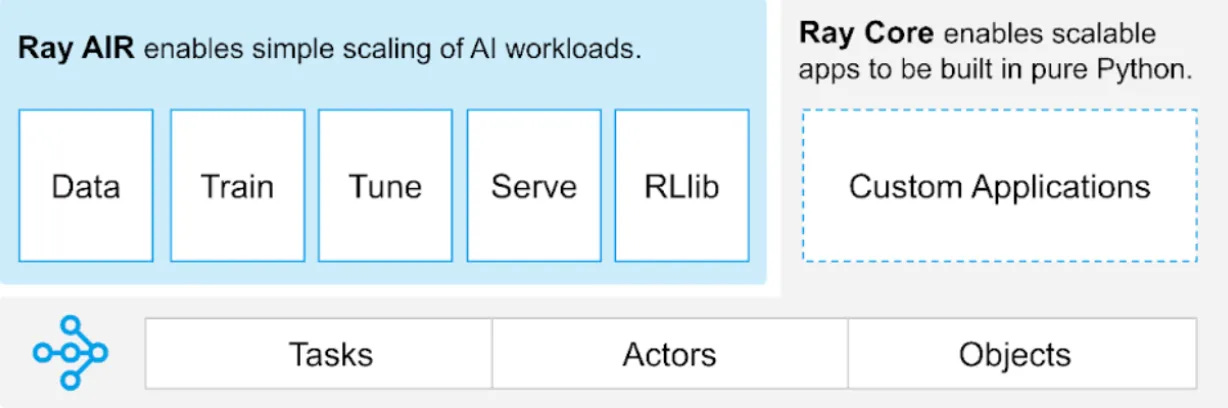
As bibliotecas disponibilizadas como parte do kit de ferramentas AIR permitem que as organizações executem toda a gama de cargas de trabalho de ML em plataformas de computação distribuídas, como a Akash Network.
Ray Serve: biblioteca de atendimento de modelo independente de estrutura que pode ser usada para construir e implantar aplicativos de inferência de IA/ML distribuídos de ponta a ponta.
Ray Tune: biblioteca para execução de experimentos de ML e ajuste de hiperparâmetros.
Ray Train: Biblioteca escalonável de aprendizado de máquina para treinamento distribuído e ajuste fino.
Fluxo de trabalho típico do Ray
O fluxo de trabalho típico de aprendizado de máquina baseado em Ray pode envolver as seguintes etapas:
1- Crie seu aplicativo de IA/ML (normalmente código Python)
2- Escreva um arquivo YAML que definirá seu cluster Ray
3- Execute comandos na CLI para ligar/desligar o cluster
4- Envie trabalhos e monitore-os através do painel (web)
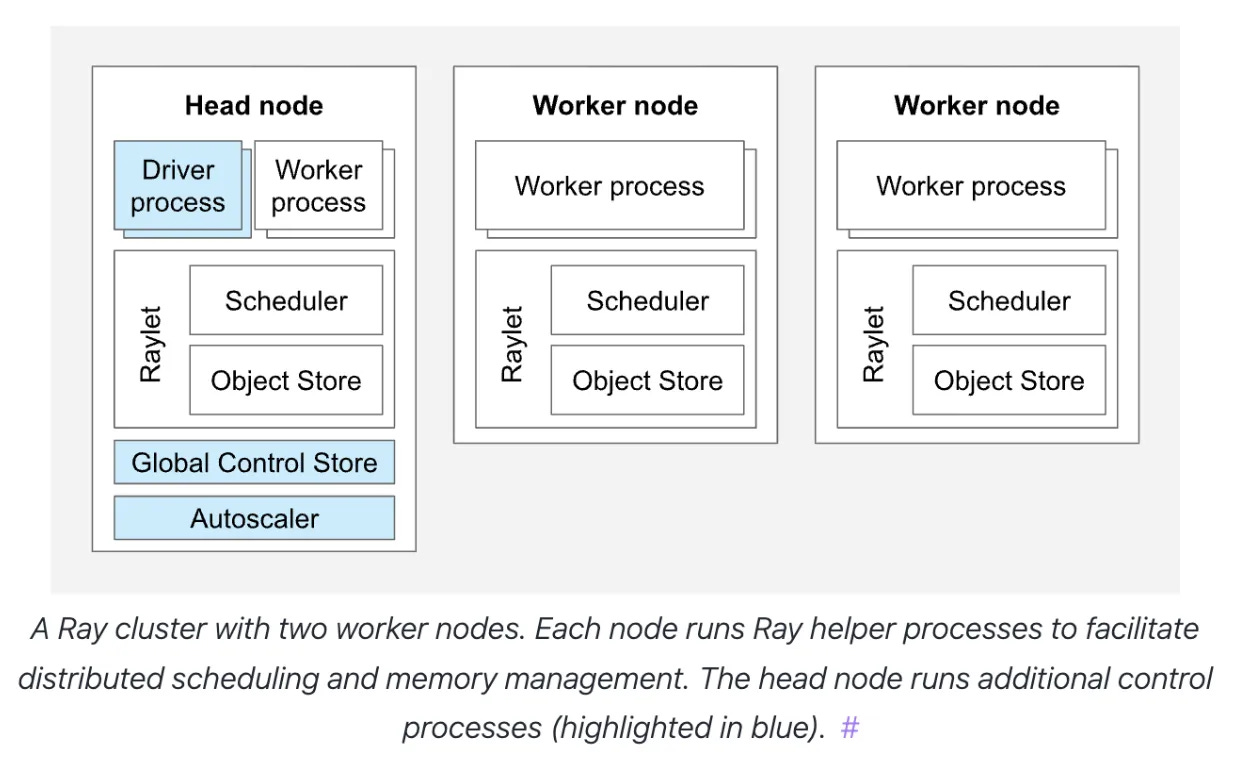
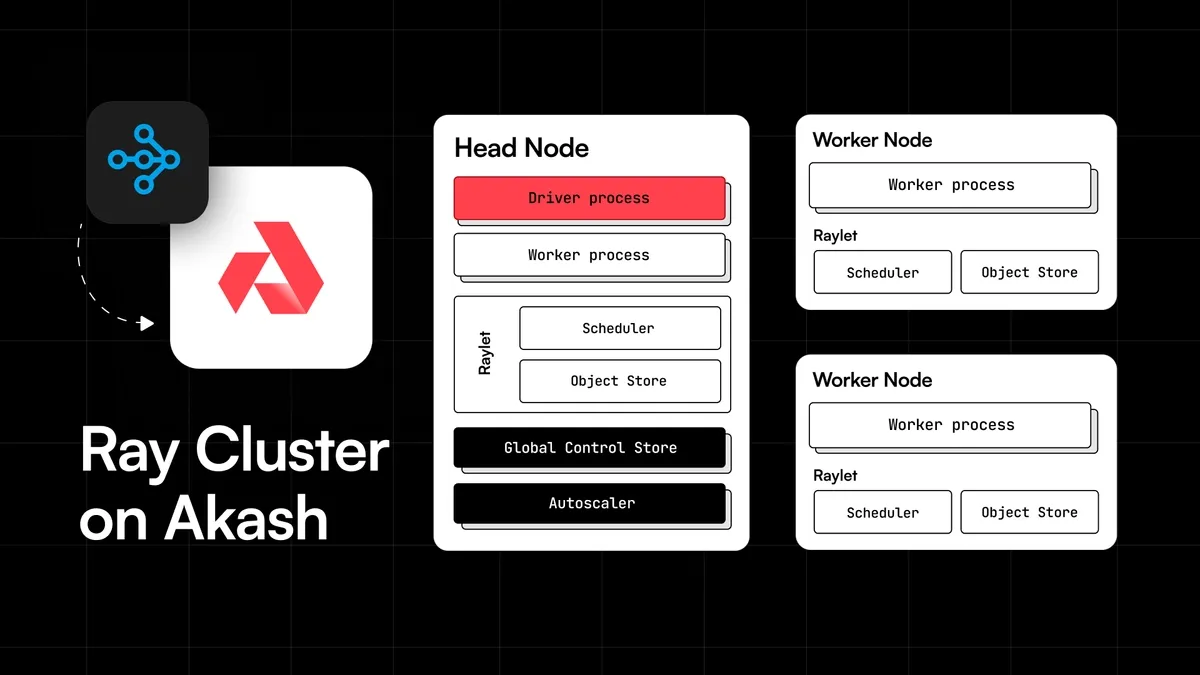
Ray em Akash
Ray é bastante agnóstico em termos de infraestrutura e funciona com contêineres Docker. Por isso, ele naturalmente se presta a ser uma ótima solução para fornecer uma abstração de um “servidor único” na nuvem descentralizada da Akash Network.
Para permitir que os usuários da Akash Network utilizem facilmente os recursos do Ray, a equipe da ThumperAI, trabalhando com a equipe do Overclock Labs, construiu um conjunto de imagens docker e um modelo Akash SDL (Stack Definition Language) que pode ser usado como referência para qualquer pessoa que queira executar Aglomerados de raios em Akash. O código-fonte disso pode ser encontrado no repositório “awesome-akash” (contém um conjunto cada vez maior de modelos de referência para executar vários aplicativos comuns no Akash) no seguinte local:
https://github.com/akash-network/awesome-akash/tree/master/ray
O modelo de referência é otimizado especificamente para cargas de trabalho baseadas em GPU e implanta um cluster Ray que consiste em um nó principal e seis nós de trabalho.
Você pode personalizar a referência de acordo com suas necessidades específicas de carga de trabalho das seguintes maneiras:
1- Para atualizar a versão do Ray, Python ou CUDA, atualize os Dockerfiles e substitua a imagem do Ray Docker usada lá, por uma daqui. A imagem usada na referência contém Python versão 3.10, CUDA versão 11.8.
FROM rayproject/ray-ml:nightly-py310-cu118
EXPOSE 6380
EXPOSE 8265
RUN sudo apt-get install git-lfs s3fs -y
RUN git lfs install --skip-repo
RUN pip install s3fs
COPY /starthead.sh .
RUN sudo chmod 777 /home/ray/starthead.sh
RUN sudo chmod a+x /home/ray/starthead.sh
RUN sudo chown ray /home/ray/starthead.sh
RUN sudo chmod 777 /home/ray
# ENTRYPOINT ["bash -c"]
CMD ["/home/ray/starthead.sh"]
Observe que você precisará reconstruir as imagens do Docker para o nó principal e o nó de trabalho e enviá-las para um registro de contêiner, se você atualizar os Dockerfiles. Siga as instruções no README para isso.
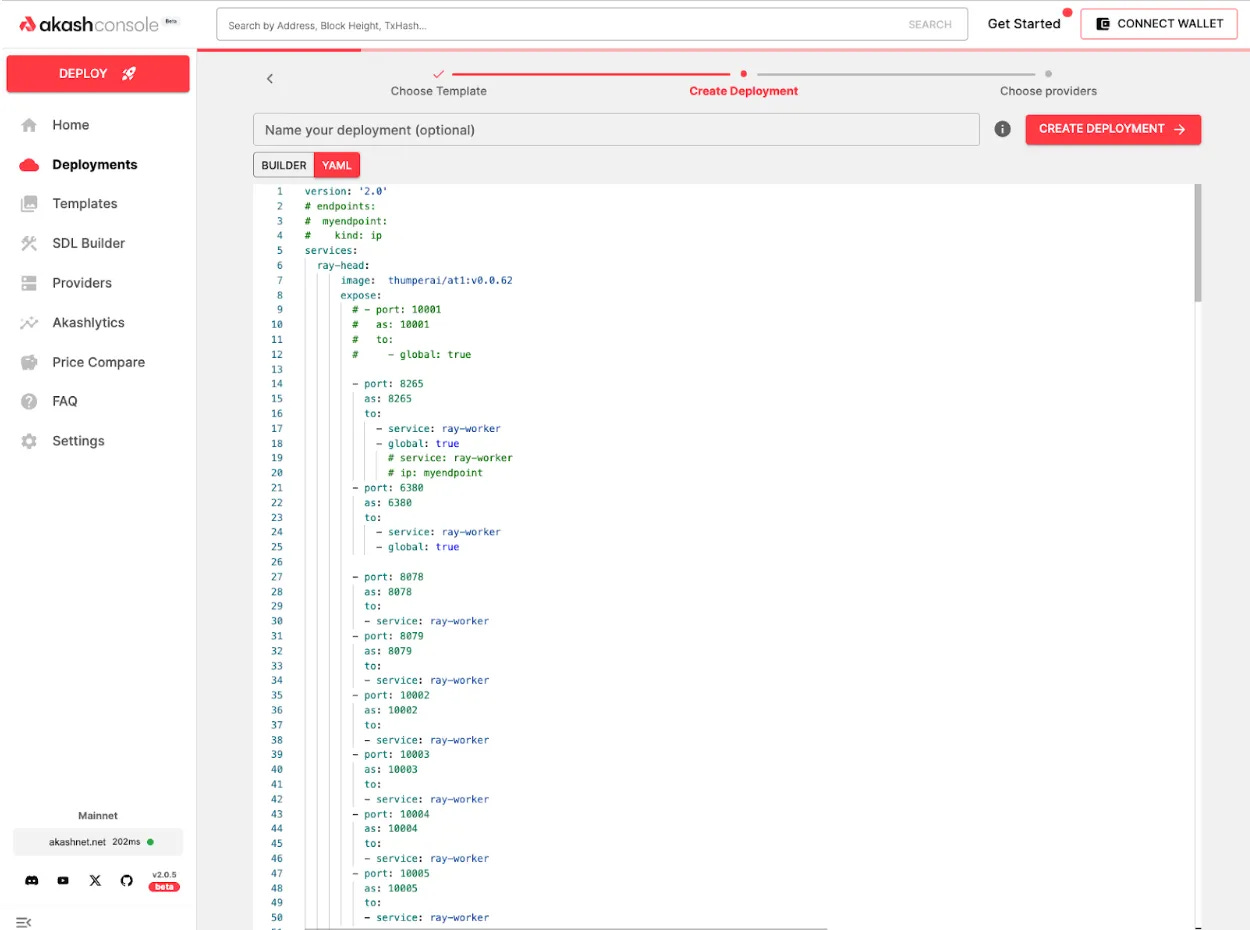
2- Para atualizar o número de nós de trabalho no cluster Ray, modifique o arquivo de exemplo de implantação (observe que a referência implanta seis nós de trabalho Ray).
version: '2.0'
services:
ray-head:
image: thumperai/rayakash:ray-head-gpu-py310
expose:
- port: 8265
as: 8265
to:
- service: ray-worker, ray-worker1, ray-worker2, ray-worker3, ray-worker4, ray-worker5
- global: true
- port: 6380
as: 6380
to:
- service: ray-worker, ray-worker1, ray-worker2, ray-worker3, ray-worker4, ray-worker5
- global: true
- port: 8078
as: 8078
to:
- service: ray-worker, ray-worker1, ray-worker2, ray-worker3, ray-worker4, ray-worker5
- port: 8079
as: 8079
to:
- service: ray-worker, ray-worker1, ray-worker2, ray-worker3, ray-worker4, ray-worker5
- port: 10002
as: 10002
to:
- service: ray-worker, ray-worker1, ray-worker2, ray-worker3, ray-worker4, ray-worker5
- port: 10003
as: 10003
to:
- service: ray-worker, ray-worker1, ray-worker2, ray-worker3, ray-worker4, ray-worker5
- port: 10004
as: 10004
to:
- service: ray-worker, ray-worker1, ray-worker2, ray-worker3, ray-worker4, ray-worker5
- port: 10005
as: 10005
to:
- service: ray-worker, ray-worker1, ray-worker2, ray-worker3, ray-worker4, ray-worker5
3- Você precisará adicionar várias variáveis de ambiente para sua chave de acesso e segredo da AWS (se estiver usando S3 para armazenamento), chave de acesso e segredo de MinIO (se estiver usando MinIO) e outras coisas:
RAY_ADDRESS_HOST: Especifica o endereço do nó principal. Edite apenas se estiver tentando usar o ray em vários provedores.
AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY: credenciais para serviços da AWS.
R2_BUCKET_URL, S3_ENDPOINT_URL: URLs para serviços de armazenamento compatíveis com S3.
B2_APPLICATION_KEY_ID, B2_APPLICATION_KEY: credenciais para armazenamento Backblaze B2.
MINIO_ACCESS_KEY, MINIO_SECRET_KEY: credenciais para armazenamento MinIO.
AWS_DEFAULT_REGION: a região padrão da AWS para serviços.
WANDB_API_KEY, WANDB_PROJECT: credenciais e nome do projeto para geração de registros de pesos e tendências.
Atualize os recursos necessários para sua carga de trabalho específica, por trabalhador, modificando a definição de serviço para ray-head e cada ray-worker no arquivo YAML do exemplo de implantação.
Depois de configurar tudo corretamente, acesse https://console.akash.network/ e use a opção do criador de modelos para implantar seu cluster Ray no Akash.
E aqui está uma rápida visão geral de como é todo o fluxo de trabalho de implantação de ponta a ponta:
Estudo de caso Ray-on-Akash - Akash-Thumper-1 (AT-1)
ThumperAI e Overclock Labs (os criadores da Akash Network) executam um cluster Ray em alguns provedores Akash há cerca de quatro meses como parte do treinamento de um novo modelo de base de IA chamado “Akash-Thumper”. Pretendemos lançar a primeira versão desse modelo (chamado “AT-1”) no Huggingface em breve.
Fique ligado em uma série de postagens no blog nas próximas semanas, que irão aprofundar os detalhes e resultados do processo de treinamento.
Primeiros passos com Ray no Akash
Você usa Ray para inferência, treinamento ou ajuste de cargas de trabalho hoje? Nesse caso, a equipe principal do Akash adoraria ajudá-lo a aproveitar a infraestrutura de GPU do Akash para suas necessidades — entre em contato com a equipe principal do Akash para continuar a conversa.